It’s widely known that the best way to make a student study a boring subject is to transform learning into a game. A long time ago someone came up with a game of this sort in the field of Cybersecurity — Capture the Flag or CTF for short. CTFs motivated lazy students to learn how to reverse engineer binaries, where best to place an apostrophe and why using proprietary encryption is a more sophisticated way of jumping on a rake.
The university students that took part in those old CTFs have grown up, so now the competitors in this “game” are seasoned professionals (usually with children and a mortgage). They’ve seen it all, so making a CTF challenge that won’t make them whine is no easy task.
However, if you make the task too tough, there will be an uproar from other teams that are focused on a different subject in cybersecurity or it’s their first time participating in a difficult CTF.
In this article I’ll try to explain how our team managed to strike a balance between “cool, something new” and “this is way too hard”, when we developed the Cryptography task for the CTFZone Finals 2020. Now let’s dive in.
Intro
If you are unfamiliar with what CTFs are, these are competitions for practitioners of applied information security. They are hosted by Infosec-related companies, CTF teams and universities. There are two types of competitions: jeopardy and attack-defense.
Jeopardy is usually hosted online, and it consists of various tasks created by the organizers. Teams get points for solving the tasks, the team with the most points wins.
Attack-defense (AD) is a bit more complicated and harder on the host’s infrastructure, so it is mostly hosted offline (for example, at conferences). Quite often teams need to place in the top 10 or 20 in a jeopardy-style qualification round to get invited to attack-defense.
At the start of AD teams are given vulnboxes — virtual machines or hosts with vulnerable services, which they need to protect. Each team receives an identical vulnbox. Teams need to secure their own vulnboxes, while keeping them available for the checking server (you can’t just shut it down and consider it secure).
At the same time they have to attack other team’s vulnboxes in pursuit to steal flags — unique identifiers that are being stored on each vulnbox by the checking server every round. Each round usually lasts 5 minutes. Teams can submit other teams’ flags and gain points. They also usually get points deducted when vulnbox is unavailable to the checking server. So the goals for each team are:
• keep your vulnbox up;
• patch it against attacks;
• attack other vulnboxes to steal flags.
If you’ve ever taken part in CTFs, you probably know that there are several basic categories:
• Web
• Pwn
• Misc
• PPC
• Forensic
• Reverse
• Crypto (i.e. cryptography, not cryptocurrencies)
Sometimes tasks belong to several of the above or resemble neither of them, but these categories are the ones you are most likely to see in a jeopardy-style CTF. Unfortunately, not all of them are suitable for AD. Not every task has an interactive component. Cryptography category also has particular problems.
Why a cryptographic task was necessary
At the initial planning phase, we were arguing whether to make a cryptographic task for AD at all. You see, usually each vulnerable service in AD has several bugs with varying degrees of difficulty. Task creators design this with less experienced teams in mind. It also helps stronger teams start pulling flags from their opponents earlier, resulting in a more dynamic game.
Unfortunately, with cryptographic tasks it is often the case that teams stop at the first bug. It is quite hard to design new simple cryptographic vulnerabilities. As a result, you have to use well-known vulnerabilities (like nonce-reuse in ECDSA), which are quickly spotted and patched by expert teams, but can often go unnoticed by rookies.
Alternatively, if you try to change the formula, sometimes you can make things worse. I once participated in a contest, where the cryptographic AD was complex and interesting and didn’t allow for such simple attacks. The downside was that only one of all the teams could steal each flag each round, because stealing a flag effectively erased it.
This can be quite frustrating for the attackers, since they’ve spent time perfecting the attack, but the profits end up being not worth the effort. So usually rolling out a cryptographic task results in either the organizer getting frustrated, because the teams haven’t dug deep enough into the challenge, or the teams being disappointed with the task. That is not a nice position to be in. So the fate of the task hung in balance.
However, we soon understood that without a cryptographic challenge, we wouldn’t have enough diversity (too much web) and in the end, we decided to create one.
The goal was to create a task, that would be hard to solve, but still doable for a newbie, and one where the effort spent on solving the task wouldn’t go to waste. Easy, right? :)
How we chose our development stack
How would we achieve this? You see, usually it is quite easy to find and fix bugs in crypto tasks, since they are most often developed in a scripting language like Python. You read the code, you notice the bug, you fix it.
We decided that it was too easy for a DEF CON qualifier, so went with Python + C for our stack (seems a bit suicidal, I know). Most of the functionality was implemented in C, while Python provided a convenient wrapper with easier socket manipulation and server functionality.
Now that we’ve decided on the stack, it was time to choose the systems we would be implementing and the bugs we wanted to introduce into those systems.
How we decided on the task idea
We didn’t want to make a task full of vulnerabilities familiar to every CTF player, so we decided to pick one of the slightly less conventional subfields: Zero Knowledge Proofs of Knowledge (ZKPoK). The idea is to prove that you know some secret without revealing the secret itself. We decided to use ZKPoK as an identification scheme: when checker proves knowledge of something, it receives the flag. The particular scheme we chose is based on Hamiltonicity.
A. What is graph Hamiltonicity?
Disclaimer. I am not a mathematician, nor am I a cryptographer. The following statements may sometimes be not mathematically correct or may leave out certain details. My goal here is to show the concepts without putting too much strain on the reader.
Let’s say there is a graph. A Hamiltonian cycle is a cycle that passes through all the vertices of the graph but only once.
Finding the Hamiltonian cycle is considered a hard problem. At the same time creating a graph with a Hamiltonian cycle is a piece of cake. Let me show you, how.
First, some background information. We chose to represent our graphs through adjacency matrices. These are square matrices, where the fact that two vertices are connected by an edge is shown by one in the corresponding cell and zero otherwise. For example, we have 4 vertices: A,B,C,D. A is connected to B, C is connected to D.
The matrix would be:
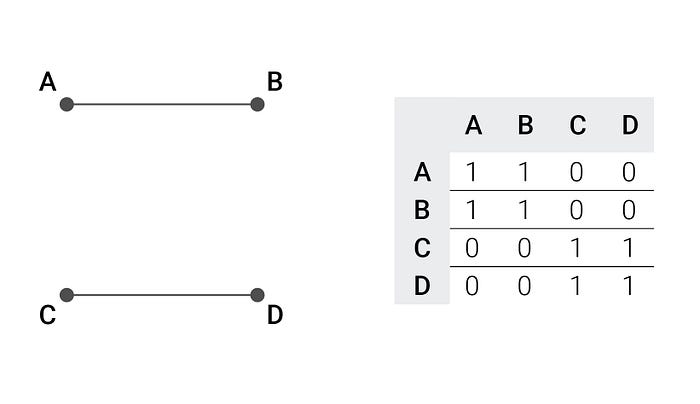
You can set the diagonal to zeros or ones, depends on what you need to do with the graph.
So, if you want to create a graph with a known Hamiltonian cycle, what you do first is shuffle the vertices: ABCD -> BADC. From this array of vertices, you derive which vertex follows which in the cycle: B->A->D->C->B. Now you translate this cycle into the cycle matrix. To do this first set all cells to zero, and then for each directed edge set the cell with row equal to source vertex and column equal to target vertex to one. So, in this case:
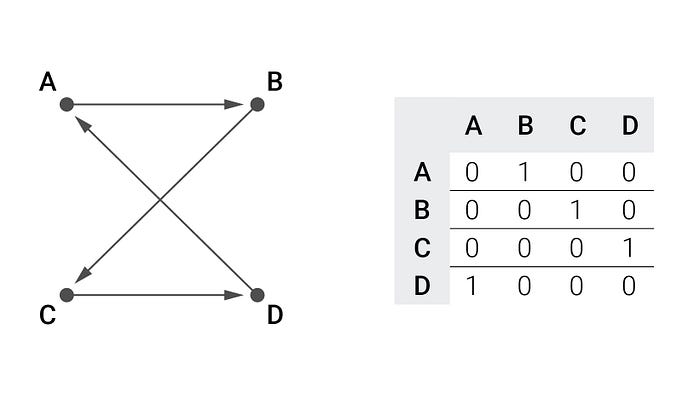
As you can see, the result is a matrix with a single 1 in each row and each column. Now that we have a Hamiltonian cycle graph, we can easily create a graph containing this cycle by adding random edges. In the task we were also working with undirected graphs, so we need to ensure that the graph is symmetric (value at position (i,j) is equal to value at position (j,i)). One possible result of those actions is the following adjacency matrix:
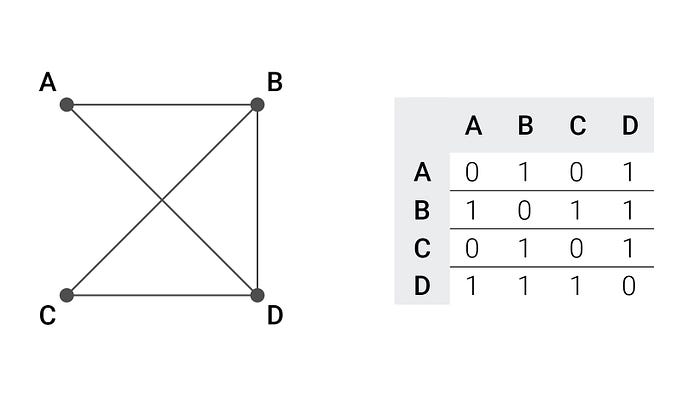
You may notice that for each edge (x,y) there is an (y,x) and I added an edge between B and D.
B. How Hamiltonicity can be used for identification
The scheme is simple:
- publish the graph with an embedded hamiltonian cycle. It should be visible to everyone;
- connect to a team server and prove, the we know the cycle without revealing the cycle itself.
The proof consists of three stages (preparation not included).We assume the role of the Prover, while the server takes the role of the Verifier.
0. Preparation stage. We create a random permutation of vertices, for example, A->B->C->D->A. Using this permutation, we create a new graph from the old one, and it will be isomorphic (relations will stay the same) to the old one. This is achieved through representing permutation as a graph, and then doing several matrix multiplications and transpositions (reflections against the diagonal). Here we can see the initial graph and the resulting graph side by side:
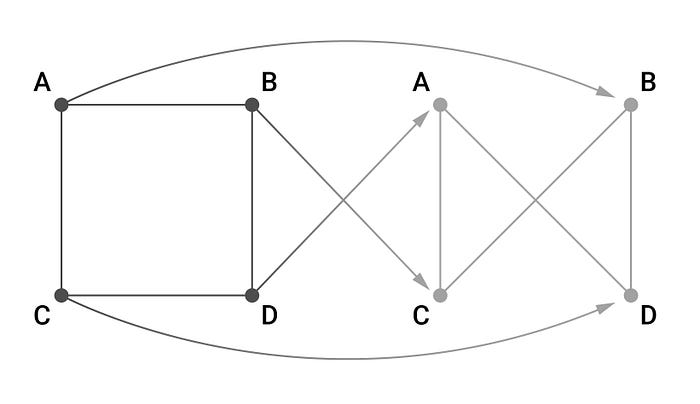
We compute a Hamiltonian cycle on the new graph by applying the same permutations to the cycle’s adjacency matrix. As a result, we have a new graph with a Hamiltonian cycle that is isomorphic to the old one.
1. Commitment stage. Now that we’ve finished the preparation phase, we send what is called a commitment to the server. In this case, the commitment contains the permuted graph and two closed containers: the first one contains the permutation we created, while the second has the permuted cycle. Both containers arrive at the Verifier sealed, so that it can’t peek inside, but the Prover can disclose their content at any time.
Commitments need to have two crucial properties:
1. Hiding. They need to hide the data inside the containers from the Verifier, so that it can’t open it without the help from the Prover.
2. Binding. Once the Prover has made a commitment, it should not be able to change what’s inside. It only has the choices of leaving the lid closed or opening it.
2. Challenge stage. So, now that the Prover has sent its commitments, the Verifier chooses a challenge bit b∈{0,1} at random and sends it to the Prover. In return, the Prover sends the information revealing either the first (if b=0) or the second (if b=1) container in the commitment.
The challenge bit is necessary to make sure the the Prover won’t know beforehand, which container he’ll need to open for the Verifier, or he will be able to trick the Prover.
3. Check stage. Now the Verifier can check whether the permuted graph is a result of the permutation being applied to the original graph, or that the Prover knows the Hamiltonian cycle on the permuted graph, depending on the challenge bit it sent earlier. If successful, the Prover will show either that the new graph is really a result of a permutation being applied to the original graph (if b=0) or that it knows the Hamiltonian cycle on the new graph (if b=1). The beauty of the proof is that the Prover can only commit to both at the same time if it knows the original Hamiltonian cycle. Without this knowledge, it can only try to guess the challenge bit that will be issued by the Verifier.
At the same time the Verifier derives no information about the original Hamiltonian cycle by opening just one of the commitments. This can be easily proven through simulation. In simulation we can reverse the protocol and change commitments after the Prover has received the challenge bit. Knowing the challenge bit it can always create a permutation of the graph or create a completely new graph with a known Hamiltonian cycle. Then it commits to the former or the latter according to the challenge bit. The Verifier issues the same bit once again and checks the revealed commitment which successfully proves Prover’s knowledge. Since in this case there was no knowledge to begin with, the Verifier can’t squeeze any information out of the proof, even when speaking to the actual Prover and not a simulation.
As you might have noticed, there is a 50% chance for a malicious Prover, with no knowledge of the original cycle, to win anyway. Now, done once, that is not secure at all. However, this sequence is not supposed to be run once. The goal is for the Verifier and Prover to do this sequence again and again several times. If it is performed twice, then the probability of cheating is 25%, three times — 12,5%, and so on. So, you can always decide on the number of steps that would satisfy your risk tolerance.
That’s the system we decided to implement as the basis of our cryptographic task.
P.S. If all this sounded like gibberish to you or you want to know a bit more about Zero Knowledge, read Dr. Mathew Green’s Zero Knowledge Proofs: An illustrated primer. He explains the concepts far better than I ever could.
How we developed the task
Further, team server = Verifier, checker = Prover, a team attacking another team’s server = malicious Prover.
Protocol: high-level view
We decided that the number of vertices in the graph had to be set by the teams themselves, so we couldn’t use the same graph for everyone. To combat this issue, at the start of each round the checker asked each team’s server, how big a graph it needs. A suitable graph with a Hamiltonian cycle was created. Next it sent to the team server:
- the graph;
- the round flag for the team
- a 16-byte random string RANDOMR received previously from the team’s server;
- an RSA signature of all the above.
The RANDOMR value was needed so that one team couldn’t reuse a packet with a valid signature to set the same graph on other teams’ servers.
This was actually, where the first bug lay. You couldn’t steal a flag this way, but you could DoS another team. The chosen signature scheme was RSA with PKCS#1 v1.5. This signature scheme is not vulnerable in general case, but there are some implementations that can be vulnerable to Bleichenbacher’s e=3 signature attack. To enable this attack, we decided to set the public key’s public exponent to 3 and implement the vulnerable unpadding algorithm (obviously, SAFE_VERSION macro was not defined):
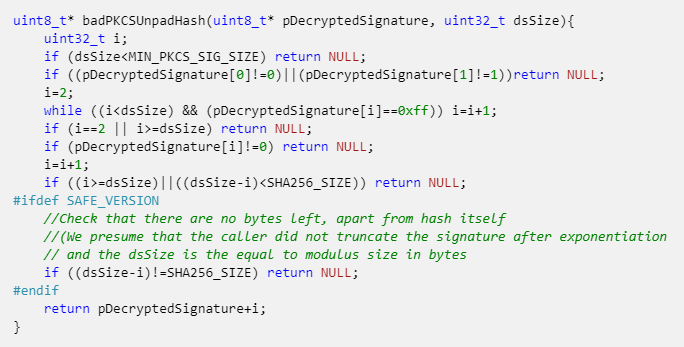
After setting the graph, each 30 seconds the checker performed the following actions:
• connected to each team server;
• requested how many checks the team sever wanted to perform;
• proved that it indeed knew the Hamiltonian cycle.
The team’s server was supposed to reply with the flag after the correct proof.
Side note: We made single proofs parallel instead of sequential to cut the number of round trips, but you should know that this can be problematic in a real setting, since sometimes such changes can break security proofs of protocols.
Protocol: internals
Now that we’ve covered the general protocol, let’s look at the vulnerabilities we‘ve introduced into the challenge.
Our language stack is Python + C. What we did was create a C library which contained 95% of application’s functionality. Then we created support classes for Prover and Verifier in Python. They held pointers to relevant structures and wrapped calls to the library (BTW, be careful with void_p in ctypes if you ever decide to use it. On x64 it can be truncated to 32 bits when it is passed as an argument to a function). The team server’s main python script contained initialization of the Verifier:

The arguments were:
- The desired number of vertices in the graph.
- The number of parallel proofs.
- The chosen commitment schemes.
Let’s cover them one by one.
Vertice count. As you can imagine, 4 vertices in a graph is not a secure configuration at all (you could easily bruteforce all cycle possibilities). We limited this parameter to a maximum of 256, since checking how long it took to find if two graphs are isomorphic took us 2 hours on a regular laptop with this parameter. Finding a cycle under those conditions in less than 5 minutes seemed optimistic at best (for our adversaries). We also didn’t want to increase the number of vertices, since the relation between proof size in bytes and the number of vertices is quadratic and we didn’t want to strain our network too much.
Number of parallel proofs. Just four parallel proofs is once again not enough. The probability of guessing proof bits correctly is 1/16. You can just try several times and you will succeed after a few attempts. Maximum value supported by the initialization function was 64, which would result in a cheating chance of 1/2⁶⁴, which is otherwise known as “fat chance”(once again, in our setting).
So, the second bug is the vulnerable vertex count and the number of proofs configuration. However, how does the third parameter affect system’s security?
Commitment schemes. The third parameter is actually a bit-mask, with 3 bits that represent if the team server has each of the three implemented commitment schemes enabled, which are:
• commitments based on crc32 hashes
• commitments based on sha256 hashes
• commitments based on aes128-cbc encryption.
Correct values for this bit-mask are 1−7, so the teams had to choose at least one algorithm. The checking server selects them in this order: crc32, sha256, AES. So, if crc32 and AES are enabled, it will prioritize crc32.
Before we dive into commitment algorithms themselves, let’s have a quick look at the implemented proof protocol:
1. Prover requests proof configuration from the Verifier (proof count and supported algorithms)
2. Verifier sends back the configuration
3. Prover creates proofs, creates commitments from proofs and sends commitments for proof_count number of proofs to the Verifier
4. Verifier sends challenge (proof_count random bits) to the Prover
5. Prover sends back information that reveals the commitments according to the challenge
6. Verifier checks that the proof is correct, sends back the flag if it is.
7. The Prover either exits or restarts from 3.
The thing is: Prover can try to start any stage of the proof at any time (like requesting the challenge before getting the commitment). In most cases the Verifier will return an error. However, by default all the teams had simulation mode enabled, which was the third bug. The corresponding configuration bit was being set up during Verifier initialization inside the compiled library. Teams had to reverse engineer the binary to find and change this. In simulation mode, after saving the commitment and receiving the challenge from the Verifier, Prover could once again send a commitment, now based on known challenge. This completely broke the protocol but was extremely easy to patch. Unfortunately, as far as we know, nobody discovered this bug :’(
Now, let us get back to our commitment algorithms.The commitments work as follows. In case of CRC32 and sha256 commitments, the permutation, permuted graph, and permuted cycle matrices are packed. Packing consists of putting the dimension of a square matrix into a single two-byte word (uint16_t) and appending the bitstream of the matrix packed tightly into bytes, so that each byte contains 8 bits from cells of the original matrix representation. After the matrices are packed, the selected hash function is applied to each packed array, so as a result there are three hashes per single proof:
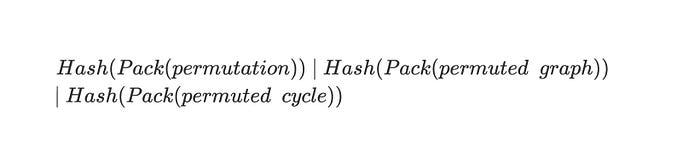
These hashes are then sent to the Verifier as a commitment. Once the Verifier sends the challenge bit b, the initial packed matrices for either permutation and permuted graph or permuted graph and permuted cycle are sent back to Verifier. Verifier can then check that the hashes correspond to the received values and the commitment is sound. If this phase is completed successfully, Verifier checks that matrices satisfy proof requirements.
In case of AES commitment, Prover creates two keys: K_1 and K_2. He packs the matrices the same way as with the other commitments, but then he encrypts the packed permutation with K_1 and packed permuted cycle with K_2. He sends both of these ciphertexts and the packed permuted graph in plaintext:
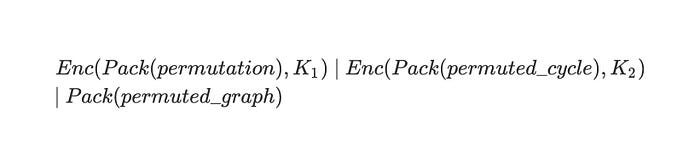
After receiving the challenge bit b from Verifier, Prover then sends back K_b (K_1 or K_2). Verifier decrypts the corresponding ciphertext and checks the validity of the proof.
As you can see, commitment based on AES succeeds in hiding the proof and binding Prover (you can’t get the permutation and permuted cycle without the keys and Prover can’t find a different key that would help them cheat). Commitment based on sha256 is also computationally binding (you’d have to find a collision) and since we don’t actually send the matrices themselves in any shape or form, they definitely satisfy the hiding property. CRC32, however, doesn’t exactly satisfy the binding property.
So, we have the fourth bug. You could bruteforce CRC32 with complexity of around 2³² to find a collision, but you can find one even faster by using the Meet-in-the-Middle approach, which will have a complexity of around 2¹⁸.
Update: it has been pointed out to me that there is even a much faster and easier approach. You can find an example of it here. However, the MITM approach still comes up for different constructions in CTFs, so it could be helpful.
The Meet-in-the-Middle attack can be used because we can reverse CRC32 rounds. Let’s say we have a y=CRC32(X_0), and we need to find some X_1, such that CRC32(X_1)=y. Let’s fix the length of X₁that we are seeking to 6 bytes (it will help later). CRC32 consists of three phases:
1. Initialization Init
2. Looping through bytes t_(i+1)=Round(t_i, b_i), where (t_i is the internal state, and b_i is the byte)
3. Postprocessing Finish
So for 6 bytes:

or as a composition of functions of t:
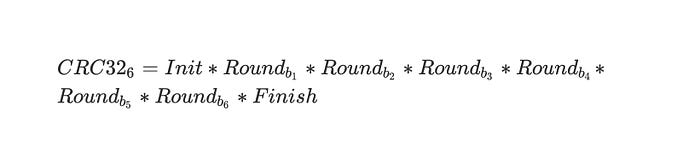
What we could do is split CRC32_6 into two halves: CRC32_FH and CRC32_SH. The first half would contain Init and the first three rounds, while the second half would contain the last three rounds and Finish. Since rounds and Finish are invertible, so is CRC32_SH, so we can define CRC32_SH_INVERTED. Once we have CRC32_FH and CRC32_SH_INVERTED we can:
- Compute around 2¹⁷ values of CRC32_FH with random b_1, b_2, b_3 and put them in a hash table, so that we can look up a precursor for each computed value of CRC32_FH in near constant time
- We compute CRC32_SH_INVERTED with the initial value of the CRC32 we are trying to find a collision to as input and random values b_4, b_5, b_6 in a loop. During each iteration we check if the result is in the hash table we compiled earlier. This should take around 2¹⁵ — 2¹⁶ iterations.
- Once we’ve found a collision in the hash table, we’ve also found a collision for CRC32. y=CRC32(b_1, b_2, b_3, b_4, b_5, b_6)
You might say: “This is all well and good, but our data shouldn’t be just random, it should be one of those matrices and it needs to pass other checks, so this was all for naught”. You would be right, if only not for the fact that we wrote matrix unpacking in such a way that it permitted appending garbage bytes. Remember how we’re packing matrices:

Well the great thing is that Verifier hashes this whole blob when it checks the HASHES, but when the matrices are unpacked, the algorithm only take size² bits from packed_data, and everything extra is discarded. So, what we can do is append extra 6 bytes:

After finding collisions, a malicious Prover can pass Verifier’s checks and get the flag.
The final vulnerability
We’ve covered how the whole system works and we’ve already discussed four intended vulnerabilities. However, there was also a fifth bug. The challenge bits submitted by Prover were sourced from an insecure PRNG (Pseudo Random Number Generator). The common choice of an insecure primitive in such cases is C’s rand , but we wanted to introduce something a bit more interesting. In recent years, there were several papers about Legendre PRF, so we chose to implement it as our PRNG instead of overused Mersenne Twister.
The idea behind the PRNG is that there is a Galois field GF(p) of quotients modulo prime number p. Every element of this field except 0 is either a quadratic residue or not. There are (p−1)/2 quadratic residues (excluding 0) and (p−1)/2 non-quadratic residues. If you pick a random element from the field except for 0 the probability of it being a quadratic residue if 1/2. It is quite easy to check if a particular element r≠0 is a quadratic residue. You have to compute its Legendre symbol. If r=(p−1)/2=1 mod p, then r is a quadratic residue. Since the probability of each r to be a quadratic residue is 50% and quadratic residues are mixed in randomly with non-quadratic residues, we can create a PRNG. We seed the PRNG with a random element a∈ GF(p). Here is the algorithm in python:

We specifically chose a 32-bit p, so that teams could use a Meet-in-the-Middle attack. The idea is to get 2¹⁶+31 bits from the PRNG by repeatedly requesting challenges. Once you have those, you can convert this bitsteam into 2¹⁶ 32-bit integers by transforming each tuple of 32 bits inside the stream into an integer. Whether to use big-endian or little-endian notation is irrelevant, the important thing is to commit to your choice.
Put these integers in a dictionary as keys, with corresponding values being their positions in the bitstream. Now initialize your own instance of LegendrePRNG. Pick a=1 and sample 32 bits. Convert those bits into an integer and check if it is in the dictionary (the cost of lookup is supposed to be close to constant). If not, change seed to a=1+2¹⁶ and repeat. Increase a in steps of 2¹⁶ until you find a match.
Now that you’ve found one, you know what the value of the internal state of Verifier’s PRNG was several steps ago. Update a to the current step and you’ve now successfully cloned Verifier’s PRNG. If you know the challenges beforehand, there is no challenge (pun intended) in cheating.
Once again, you may ask: “Wouldn’t there be a problem, if several teams were attacking at once?”. We thought of that, and designed individual connections to spawn independent PRNG states. This way teams couldn’t affect each other’s connections.
To sum up the vulnerabilities present in the service:
1. Bleichenbacher’s e=3 signature forgery attack
2. Unsafe Verifier parameters
3. Enabled simulation mode
4. CRC32 commitment
5. Insecure PRNG
Development quirks
Frankly, writing the task was quite fun.
At the early stages, we decided that we wouldn’t add any dependencies except for standard libraries. For example, because of this, we had to use Linux Usermode Kernel CryptoAPI for our hashing and encryption needs.
Since we were writing the matrix library from scratch, we soon stumbled upon latency issues. Matrix multiplication simply took too long. We didn’t use SIMD, so there was a limit to how fast we could make it. Fortunately, we quickly noticed, that we didn’t actually need general matrix multiplication, our case was special. We needed matrix multiplication just for calculating permuted graph and cycle matrices.
Let’s say you have a graph or cycle matrix M and permutation matrix P. To find the permuted matrix Mp you need to compute Mp=Pᵗ⋅M⋅P. Permutation matrices are a special case. Each row and each column of a permutation matrix contains just a single 1 all the other cells are filled with 0s. The same is true for transposed permutation matrix. So let’s say we multiply such matrix P′ with M′, R=P′⋅M′.
As you know, we multiply matrix rows by columns. So, since there is only one 1 in each row and column we can:
1. Take the first row of P′
2. Search for the position of 1, let’s say it is j
3. Take j-th row of M′ and copy it into the first row of R
4. Repeat for other rows
Let’s look at an example:
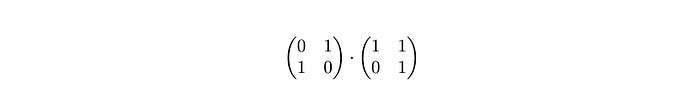
We start by searching for the first occurrence of 1 in the first row of the left matrix (P′).
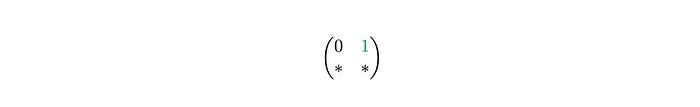
The 1 is at the second position, so we take the second row of M′ and copy it into first row of resulting matrix R.
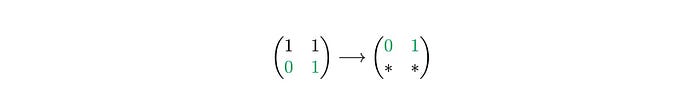
We repeat the search for the second row of P′.
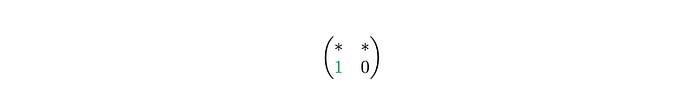
It’s at the first position in the row, so we take the first row of M′ and copy it into the second row or the resulting matrix.
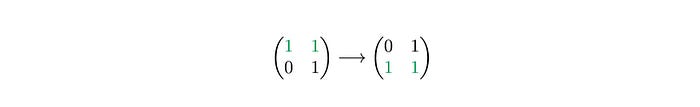
This way we can easily get the resulting matrix.
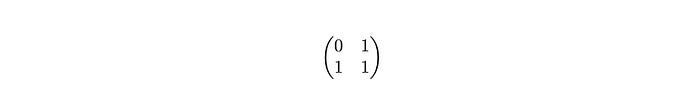
Since we know that there is only one 1 in each row, we know, that only the j-th index of each column will affect the resulting cell. What’s more, since we are using memcpy for copying, we are actually speeding up multiplications with SIMD, since memcpy uses it for faster duplication. This method sped up our calculations significantly.
The final service was built into a docker container through a two-stage build. First, the Zero- Knowledge library was built separately, then the already compiled library was copied into the final container, along with a wrapper python script, a server script and the public key of the checker in PEM format. All symbols except for imported and exported were stripped from the library, so that the teams would need to reverse engineer core functionality.
Testing
As you might imagine, the task had to go through some rough testing.
First, we ran the task and the checker for a day, with the checker submitting several hundred requests to the service per second. This revealed a hard to spot bug in the CryptoAPI usage. I forgot to close one of the AF_ALG sockets, which resulted in the service quickly running out of available file descriptors.
We also tested each of the bugs, and noticed some implementation issues, which made those bugs unpwnable. As a result, we had to change parts of the application several hours before the start of the competition. Furthermore, we submitted our task to several of our colleagues to ensure no unintended bugs in logic.
What we were afraid of most, however, was unintentionally leaving exploitable binary bugs. We didn’t want it to become the second PWN task without our knowledge. The architecture of the application made this quite possible. We took several steps to mitigate this risk.
First, we recreated the full interaction between Prover and Verifier in C with all commitments and with lowest and highest possible number of vertices and number of proofs. We built this test with ASAN (Address Sanitizer), which helped find several leaks.
Second, we wrote out all interfaces, which would accept untrusted input be that on Verifier’s or Prover’s side. For each of those APIs we saved inputs created during interaction between the checker and the team’s server. Then we wrote Libfuzzer harnesses for each of those entry points, with all the necessary initialization and cleanup.
However, our library couldn’t be prepared for fuzzing as easy as that. When you fuzz, you need to make things as deterministic as possible. So, we replaced all reads from /dev/urandom with calls to rand, and replaced random initialization with srand(0). It was also obvious that fuzzing would fail to pass hash checks and create ciphertexts with valid matrices. So, for the fuzzing build we disabled all hash checks and replaced AES encryption with just copying data. Cumulatively, our fuzzers ran for several days, discovering a plethora of bugs. But after this we felt much safer when subjecting our library to the teams’ analysis.
We did everything we could to test our service against unforeseen attacks. The only thing left was to protect attackers against trivial defenses that would mitigate certain vulnerabilities easier than intended.
Anti-cheat
The Legendre PRNG bug requires lots of queries to the Verifier. We didn’t want team servers to just drop connections in an event of multiple sequential challenge requests. To dissuade teams from implementing such basic and boring mitigations we diversified checker functionality.
At the start of each round the checker would store the flag and matrix for the round on the team’s server and immediately run one instance of Proof of Knowledge protocol to pull the flag back. After that, the checker was called every thirty seconds and needed to confirm that the flag hadn’t been corrupted and the server’s behaviour didn’t deviate from the norm. To do this, we’ve designed the checker to pick one of three strategies on each call:
- Simple pull. Checker simply proves that it knows the cycle. Anything goes wrong — team’s SLA (Service Level Agreement) points are deducted.
- Checker creates valid commitments, but before sending them to the team’s server, damages them in a random fashion, ensuring that the Verifier will treat the resulting commitment as erroneous. It repeats the cycle of wrong proofs for several seconds. Then it completes one correct interaction and pulls the flag. If at any point the answer from the team’s server is an unexpected one, or the server drops connection, team loses SLA points.
- Checker initializes the protocol, sends a valid commitment. Then it tells the Verifier to send the challenge in a loop for several seconds. After the time runs out, it picks the latest challenge, creates a packet that reveals the commitment and sends it to the team’s server. If the server replies with the flag, everything is alright. Any deviations from checker’s expectations are once again penalized by deducting their SLA points.
One of the teams (Bushwhackers) had an SLA of around 65%. This was the result of them failing the second strategy. By the way, we displayed all reasons for failing teams on the scoreboard, so teams could infer that certain defense strategies were defective from the scoreboard hints.
Conclusion
When I started writing this article, I didn’t expect to drag this out for so long, but I didn’t want to leave out anything important.
Writing the task was fun, and I was thrilled to see that it didn’t fail us once throughout the whole competition. As was expected, teams didn’t find all bugs, but there was a show of decent effort. I hope that the contestants had fun with our task.
If you want, you can build and run our task yourself here: https://github.com/bi-zone/CTFZone-2020-Finals-LittleKnowledge. We’ve open-sourced the challenge so that anyone could try solving it. We provided heavy commentary for all functions inside the library, so you can choose whether you want to try the original experience or peek into the source code. A primitive implementation of the checker is also available. We hope that this will not go to waste (especially, since we poured lots of effort into it). Maybe some CTF training group will use it for educational purposes.
Thanks for reading and good luck!
P.S. If you have any questions about the task and want to reach out, here is the team:
• Alina Garbuz (a.garbuz@bi.zone) responsible for matrix library;
• Igor Motroni (i.motroni@bi.zone) responsible for the Legendre PRNG implementation;
• Innokentii Sennovskii (i.sennovskiy@bi.zone, twitter: rumata888) responsible for whatever’s left.
